
苏州纳米所刘欣研究员等在深度学习优化算法研究方面取得进展
发布日期:2022-03-17 浏览次数: 【大中小】 【关闭】
近年来,在材料科学、人工智能芯片等前沿领域,深度学习(Deep Learning)受到广泛的研究和应用。具体来说,深度学习通过学习样本数据的内在规律和表示层次实现机器像人一样具有分析和学习的能力,因而在材料科学研究中可以帮助分析高维、非线性的特征数据;在人工智能芯片研发中可以提供高效、通用的网络模型。区别于传统的浅层学习,深度学习一般具有深层的神经网络模型结构,比如目前最复杂的深度模型BERT含有1亿个以上的参数。因此,深度模型的训练(也就是求解模型的参数)一直是一项具有挑战性的任务。
一般来说,求解深度模型参数的训练算法具有两个重要的性能指标:算法的收敛速度和泛化能力。目前,应用较广泛的训练算法是随机梯度下降算法(SGD)和学习率自适应的随机梯度下降算法(如Adam和AdaBelief),其中SGD具有良好的泛化能力,但是收敛速度缓慢;Adam和AdaBelief具有较快的收敛速度,但是泛化能力不如SGD。因此,使优化算法同时具备良好的泛化能力和快速的收敛速度一直是深度学习领域内的研究热点之一。
中国科学院苏州纳米技术与纳米仿生研究所刘欣研究员、周扬帆等针对学习率自适应的随机梯度下降算法Adabief在强凸条件下的收敛速度是否可以进一步提高的问题进行了首次尝试,并给出了肯定的答案。团队利用损失函数的强凸性,提出了一种新的算法FastAdaBelief(算法伪代码如图1所示),该算法在保持良好的泛化能力的同时,具有更快的收敛速度。

图1:FastAdaBelief算法伪代码
该团队根据理论证明的结果,进行了一系列的实验研究,验证了所提出的算法的优越性。首先,在softmax回归问题上的实验验证了FastAdaBelief比其他算法的收敛速度更快(如图2所示);然后,在CIFAR-10数据集上完成了多组图像分类任务,结果表明,在实验对比算法中,FastAdaBelief具有最快的收敛速度(如图3所示),并且具有最好的泛化能力(如图4所示);最后,在Penn Treebank数据集上的文本预测任务中,FastAdaBelief算法可以最快训练出深度模型,并且得出的模型具有最小的混沌度(如图5所示)。重要的是,该团队发现FastAdaBelief在损失函数为强凸和非凸的情况下收敛速度都是最快的,因此证明了它作为一种新的基准优化算法的巨大潜力,可以广泛应用于各种深度学习的场景中。
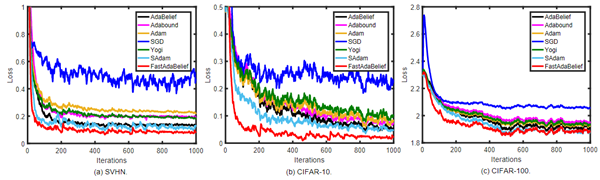
图2:softmax回归问题中各算法的收敛速度对比
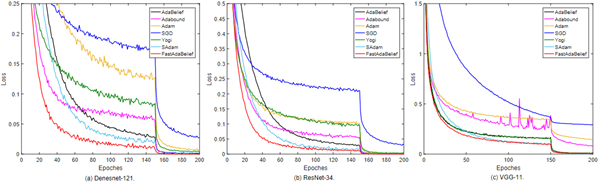
图3:CIFAR-10数据集上各算法的收敛速度对比
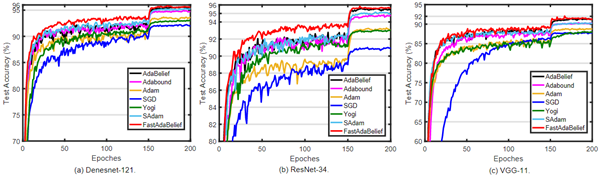
图4:CIFAR-10数据集上各算法的泛化能力对比
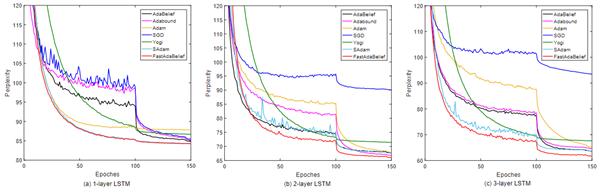
图5:Penn Treebank数据集上各算法的收敛速度对比
综上,该研究工作从理论上证明了FastAdaBelief的收敛速度比其他自适应优化算法快,并且通过大量充分的实验验证了该算法的泛化能力比其他自适应优化算法强,这可以帮助完成很多场景下的深度模型训练任务,尤其是在样本数据短缺、硬件计算算力不足的情况下。因此,在材料科学研究领域和人工智能芯片研发领域都具有很大的应用前景。
相关工作以 FastAdaBelief: Improving Convergence Rate for Belief-based Adaptive Optimizers by Exploiting Strong Convexity 为题发表在 IEEE Transactions on Neural Networks and Learning Systems 期刊上。文章作者为博士研究生周扬帆(第一作者)、王旭光研究员、程诚副研究员、昆山杜克大学黄开竹教授和爱丁堡龙比亚大学Amir Hussain教授,通讯作者为刘欣研究员。该工作得到了中科院“率先行动”引才计划(No. Y9BEJ11001)等项目的资助。
 扫一扫关注我们
扫一扫关注我们